
生成AIに潜む「ハルシネーション」というリスクをご存知ですか?
ハルシネーションとは、AIが虚偽の情報をもっともらしい形で出力してしまう現象のことで、なんと企業が訴訟される問題にまで発展しています。
また、訴訟はされずとも、ハルシネーションを知らずに生成AIを利用し続けることで、企業や個人の信頼を失う可能性もあるので注意しなければなりません。
今回の記事では、ハルシネーションの概要や原因、対策方法、検知する方法について詳しく解説します。この記事を最後まで読めば、ハルシネーションをバッチリ対策できるようになるので、企業や個人の信頼を失わずに済みますよ。ぜひ、最後までご覧ください!

ハルシネーションとは
ハルシネーションとは、AIが事実に基づかない虚偽の情報を生成してしまう現象のことです。本来は「幻覚」を意味する言葉ですが、AIが幻覚を見ているかのように「もっともらしい嘘」を出力するため、このように呼ばれています。
ハルシネーションは、主に画像や文章の生成などにおいて問題になるケースが多いので、情報を受け取る側の方も注意することが大切です。
なお、その他の生成AIリスクと対策方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。

ハルシネーションの種類
AIのハルシネーションには、異なるタイプがあり、それぞれが異なる形で誤った情報を生成する仕組みを持っています。主なハルシネーションの種類には、以下のようなものがあります。
事実ハルシネーション
AIが実際には存在しない情報を事実として提示する現象です。例えば、歴史的な人物やイベントについての質問に対して、実在しない出来事や架空の人物を作り出すことがあります。
これは、モデルが学習データから誤った関連付けを行い、信憑性のない情報を生成することが原因です。
文脈ハルシネーション
AIが、文脈にそぐわない情報を応答として生成する場合です。たとえば、あるトピックに関する質問に対して、関連性のない別のトピックに関する回答を行うことが挙げられます。
これは、AIがユーザーの質問や意図を正しく解釈できず、誤った情報を提供する際に発生します。
構造ハルシネーション
正しい質問に対しても、AIが誤った構造やフォーマットで回答を生成する現象です。例えば、リスト形式で答えるべき質問に対して、AIが段落形式で応答したり、期待される数値やデータをテキストの形で提供してしまう場合です。
これは、AIが適切な回答形式を誤認した場合に発生します。
創造的ハルシネーション
完全に架空の情報や新しい概念をAIが生成する現象です。たとえば、科学的な質問に対して、現実に存在しない理論や用語を作り出すことがあります。
これは、AIが「創造的」な思考を行う際に事実を無視して、独自の回答を生成することにより生じます。


ハルシネーションが原因で訴訟になった事例
実は、ハルシネーションが原因で訴訟にまで発展した事例が存在します。訴えられたのは、ChatGPTを開発したことで有名なOpenAIです。
マーク・ウォルターズ氏の例
訴訟を起こしたのは、「アームド・アメリカ・ラジオ」というラジオ番組の司会者を行なっているマーク・ウォルターズ氏。こちらの男性が係争中の実際の訴訟について説明を求めたところ、「ウォルターズがセカンド・アメンドメント財団から資金をだまし取り、不法に自分のものにした」とありもしない事実を、なんと虚偽の告訴状まで作って回答されたとのことです。
当然、マーク・ウォルターズ氏は詐欺や横領を働いていないので、名誉を毀損されたとして訴訟を起こしています。※1
スティーブン・シュワルツ氏の例
アメリカの弁護士スティーブン・シュワルツ氏は、クライアントの訴訟のためにChatGPTを使用して法的調査を行いました。シュワルツ弁護士は、ChatGPTが提供した6件の裁判例をもとに法廷での主張を展開しましたが、後にその裁判例が実在しないものであることが判明しました。
ChatGPTは実際には存在しない判決を捏造し、それらを本物の裁判例として引用したのです。このことで、シュワルツ弁護士と彼の法律事務所は裁判所から5,000ドルの罰金を科されることになりました。※2


ハルシネーションが起こる原因
ハルシネーションが起こるのは、主に以下の4点が原因として考えられています。
- 学習データの誤り
- 文脈を重視した回答
- 情報が古い
- 情報の推測
それぞれの原因を詳しく見ていきましょう。
学習データの誤り
AIは、インターネット上に存在する大量のデータを学習源としています。インターネット上には、不正確な情報も多く存在するので、これらを学習してしまった結果、ハルシネーションを起こしてしまうという仕組みです。
とくに、問題視されるのが、偏った見解やフィクションも学習の対象になるということです。誤った学習データを基に生成された情報は、もちろん誤った情報になるので注意しなければなりません。
文脈を重視した回答
AIは、情報の正確性よりも文脈を重視して回答を生成することがあります。これは、入力されたプロンプト(指示文)に対し、自然な形で回答しようとしているからです。
しかし、文章を最適化する過程で情報の内容が変化してしまうことがあるため、正確ではない情報が出力されます。
情報が古い
時代が変化することによって、昔の常識が現代では通用しないということがよくあります。最新の情報に関しては、AIの学習データに含まれていない可能性があるので、ハルシネーションが起きてしまうというわけです。
ちなみに、ChatGPTが出力する内容は、無料版のGPT3.5であれば2021年9月までの情報、有料版のGPT-4であれば2023年4月までの情報を学習源としています。それ以降の情報に関する質問を行なっても、正確な回答は得られないので注意しましょう。
情報の推測
AIは、学習データを基に、推測した情報を出力することがあります。これは、ユーザーが求める情報を提供しようと、無理やり回答を生成してしまうためです。
推測で出力された情報は、あくまで予想に過ぎないので、正確な情報とはいえません。出力された文脈だけでは、推測で出力されていることを見極めにくい場合もあるので注意しましょう。
アルゴリズムの限界
大規模言語モデル(LLM)は、与えられた文脈に基づいて次に来る単語を予測するように設計されていますが、この予測が必ずしも事実に基づいていないことがあります。
特に外部のデータベースにアクセスせず、訓練データだけをもとに判断を行うため、誤った情報を生成することがあるのです。
また、LLMは大量のデータからパターンを学習するものの、データの偏りや不十分さによって間違った関連付けを行い、架空の事実や文脈を作り出すことが多いです。この設計上の限界が、AIが現実には存在しない情報を生成する要因となっています。
ハルシネーションの具体例
ここでは、実際にChatGPT-3.5(無料版)を使用して、どのようにハルシネーションが起きるのかを紹介します。ハルシネーションは、事実ではないことを本当のことのかのように出力するため注意が必要です。以下を参考に、ハルシネーションがどのように起きるかを参考にしてください。
架空のアニメに関する質問
架空のアニメ「綺麗なクレヨンしんちゃん」について聞いてみました。
ChatGPTの回答はこちらです。

本当にこの映画が公開されているのか調べると、1992年にクレヨンしんちゃんはテレビアニメの放送が開始されていました!そして、1993年に最初の映画が公開されました。そのため、1992年に公開された「綺麗なクレヨンしんちゃん」という映画はありません。
しかし、ChatGPTは「綺麗なクレヨンしんちゃん」についてあらすじから特徴まで詳しく説明しています。ここまで具体的に出力されていると、騙されてしまいそうですね。
湖に関する質問
「日本で2番目に大きい湖」について聞きました。
回答はこちらです。

まさかの「琵琶湖」が2番目に大きい湖として出力されました。日本で1番目に大きい湖は「琵琶湖」です。そのため、ChatGPTは間違った情報を出力しています。
2番目に大きい湖で「琵琶湖」が出たので、1番目に大きい湖も聞いたところ「琵琶湖」が出力されました。これでは、ChatGPTが出力する情報を信用することは危険ですね。
地理に関する質問
「日本で2番目に広い都道府県」について聞きました。

ChatGPTは、2番目に広い都道府県は「青森県」と出力しました。実際に調べたところ、2番目に広い都道府県は「岩手県」でした!ChatGPTが回答した「青森県」は、8番目に広い都道府県です。
ついでに、1番広い都道府県を聞いたところ「北海道」と回答し正しい情報でした。ChatGPTは、間違った情報を出力したり、正しい情報を出力したり全ての情報を信じることはできませんね。
歴史上の人物についての質問
歴史上の人物「加藤清正」について聞きました。

加藤清正の生涯について詳しく出力されていますが、間違った情報が出力されています。加藤清正は1563年生まれではなく、1562年生まれです。また、肥前国(現在の長崎県)出身ではなく、尾張中村(現在の愛知県名古屋市)出身です。
しかし、全て間違っている情報ではなく、1611年に加藤清正は亡くなっています。
架空の戦いについての質問
実際に存在しない「御所浦の戦い」について聞きました。

存在しない戦いなのに、詳しく説明されています。加藤清正について聞いた時に出力されていた「肥前国」がまた出力されています。しかも、今回は佐賀県の唐津市と回答しています。
先ほどの回答では、長崎県と出力していたのに嘘の情報です。ハルシネーションは、このような形で出力されるので必ず正しい情報か確認することが重要です。
ハルシネーションが起きやすい質問の仕方
ハルシネーションは、以下のような質問をすることで起きやすくなります。
- プロンプトに嘘の情報が入っている
- 架空のことに関する質問
- 歴史や時事問題についての質問
先ほどの事例のように、架空のアニメや嘘の情報について質問することでハルシネーションが起きやすくなります。そのため、ChatGPTに質問する際は、正しい情報かどうか確認しましょう。
また、歴史や時事問題についての質問もハルシネーションが起きやすいです。歴史上の人物や戦いのように、生まれた年数が間違っていたり、存在しない戦いについて詳しく説明したりします。
ChatGPTが出力した情報を信用せず、正しい情報か確認することが大切です。ハルシネーションが起きやすい質問の仕方は避けましょう。
なお、リスクを避けるために身に付けるべきAIリテラシーについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

生成AIを社内で利用する際のハルシネーション対策
生成AIを社内で利用する際は、ハルシネーション対策を事前に講じておくことが大切です。具体的には、以下6つの対策を行いましょう。
- アルゴリズムの改善
- データ品質の向上
- 偽情報や不正確な情報を回答することを念頭におく
- ガイドラインを作成する
- 回答結果の確認プロセスを構築する
- Gemini(旧Google Bard)を利用する
それぞれ具体的な対策を以下で解説していくので、ぜひ参考にしてみてください。
アルゴリズムの改善
AIのハルシネーションを防ぐためには、アルゴリズムの改善が重要です。特に、生成AIが次の単語や文を予測する際、より正確で文脈に即した結果を生成できるよう、モデルの設計を改善することが求められます。
例えば、強化学習によるフィードバックループや、より精密な注意メカニズムを導入することで、AIが過去の情報やデータを適切に参照し、誤った推論を減少させることができます。
データ品質の向上
AIが学習するデータの品質が、生成される情報の正確性につながります。したがって、訓練データの品質を向上させることがハルシネーション防止の鍵となります。
具体的には、信頼できる情報源や一次データに基づいた学習データセットを活用し、ノイズや誤情報が含まれるデータを排除することです。また、データの偏りを抑えるために、さまざまな分野やソースからバランスの取れたデータを収集し、AIモデルが多角的な視点から情報を分析できるようにすることも必要です。
偽情報や不正確な情報を回答することを念頭におく
まずは、AIが偽情報や不正確な情報を回答する可能性があることを念頭におきましょう。あらかじめ予測ができていれば、ハルシネーションによる被害を防ぐことができます。
とくに危険なのが、「AIが出力する情報はすべて正しい」という思い込みです。文脈が整理されており、どこか説得力のある文章に見えてしまいますが、まずは疑うところから始めてみてください。
ガイドラインを作成する
生成AIの利用に関するガイドラインを作成しておくことも、ハルシネーションの対策として有効です。とくに、生成AIを利用する際の注意点を従業員全体に周知しておくことで、ハルシネーションによる被害を軽減できます。作成したガイドラインは、メールや書面にて全従業員に通達するほか、ポスターなどで目立つ場所に掲示しておくとよいでしょう。
また、文部科学省や総務省など行政機関からも生成AIの取り扱いに関するガイドラインが発表されています。そちらを活用するのも有効な対策となります。※3
回答結果の確認プロセスを構築する
生成AIで情報を出力した後は、必ず回答された情報の整合性をチェックすることが大切です。毎回確認するようにプロセスを構築しておけば、自然とハルシネーションによる被害が減っていきます。
情報の正誤を判断する際は、以下を参照するのがおすすめです。
- 公的機関や行政のサイト
- 専門家が運営しているサイト
- 企業のサイト
- 新聞記事
- 論文や学術記事
基本的には、信頼できる1次情報から内容を確認し、AIが出力された情報が事実に基づいていることを確かめましょう。
Gemini(旧Google Bard)を利用する
Gemini(旧Google Bard)が2023年9月のアップデートで、「ダブルチェック」という機能を実装しました。これは、生成した内容をGoogle検索し、生成した文章のどの部分が正しい情報で、どの部分がAIによるハルシネーションなのかを識別できる機能です。
これにより、AIによる生成内容をAI自身が検知できるようになりました。
生成AIを開発する際のハルシネーション対策
生成AIを自社で開発する際もハルシネーション対策を行う必要があります。有効な対策法を以下にまとめました。
- 学習データの質の向上
- 出力の結果にフィルターをかける
- RLHF
- グラウンディング
以下でそれぞれ、詳しい対策方法を解説していきますね!
学習データの質の向上
生成AIは、どのようなデータを学習するかによって、情報の出力結果が変わります。学習データの質を向上させれば、実際に生成AIを運用する際に、誤った情報を出力する可能性を下げられますよ。
具体的には、誤りがある情報を極力排除することで、ハルシネーションの発生を抑えることが可能です。しかし、大量のデータに対して、学習データの取捨選択を行うのは非常に労力がかかるので、完璧に対策できるわけではありません。
出力の結果にフィルターをかける
フィルターは、出力結果から誤りや不正確な情報を除去する役割を果たします。出力の結果にフィルターをかければ、偏りのある情報や誤った情報を出力しないように制限をかけることが可能です。
ただし、AIは情報の正誤を厳密に見極めることが難しいため、こちらも完璧な対策法とはいえません。
RLHF
RLHFは、Reinforcement Learning from Human Feedbackの略です。「人間のフィードバックからの強化学習」という意味の通り、人間の価値基準に合うように言語モデルをチューニングすることを指しています。
OpenAIのInstructGPTやChatGPTにもこの手法が取り入れられており、同社がリリースしていたGPT-3と比較して、大幅にハルシネーションの発生を抑えることに成功しています。※4
グラウンディング
グラウンディングとは、AIを活用するユーザーが指定した情報源だけに基づいて、AIに回答を生成させることを指しています。
通常は、AIが事前に学習した大量のデータに基づいて回答を生成しますが、グラウンディングでは事前に学習した情報は使いません。そのため、誤った情報を学習した結果、ハルシネーションが起きるというリスクを軽減できるというわけです。
GoogleCloudが提供している「Vertex AI Search and Conversation」では、すでにグラウンディングをAIチャットボットに実装する仕組みが搭載されています。
なお、ChatGPTを企業利用するリスクと対策方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。

生成AIを開発する際にハルシネーションを防ぐためには
生成AIを開発する際にハルシネーションを防ぐためには、エンベディングを行うことが有効です。エンベディングとは、生成AIに独自のデータを学習させることを指しています。
エンベディングでは、まず独自のデータを集めたベクトルデータベースを作成します。生成AIが回答を出力する際は、作成したベクトルデータベースから、質問との類似度が高い数値を持つデータを検索し、回答するという仕組みです。
あとは、独自データを学習させる段階で、誤った情報さえ取り込まなければ、ハルシネーションの発生確率を格段に抑えられますよ。
さらに、アルゴリズムの改善も重要です。強化学習を使って、AIが間違った情報を生成した場合にフィードバックを行い、次回の生成精度を向上させる仕組みを取り入れたり、ドメイン固有のルールを反映させるために、生成過程を精密に調整することで、ハルシネーションを防げます。
ハルシネーションの完全な対策は困難
ハルシネーションは、企業や個人の信頼を一瞬で落としてしまいかねない、決して無視できない問題です。このハルシネーションが頻繁に発生してしまえば、誰もインターネット上の情報を信じられなくなってしまうでしょう。
ただ、このハルシネーション問題を完全に防ぐのは難しいのが実情です。そのため、ハルシネーションは起こって当たり前というスタンスで生成AIを利用していくのが無難となります。
逆に、ハルシネーションさえなくなれば、AIを使った情報収集が格段に捗るようになりますね。そのうち、Webサイトの情報はすべてAIが作成する時代が来るかもしれません。
なお、ハルシネーションの問題を調査するために行われた研究結果について詳しく知りたい方は、下記の記事を合わせてご確認ください。

AIを使ったハルシネーション対策AIの開発
弊社では、ハルシネーション対策ができるAIの開発実績があります。
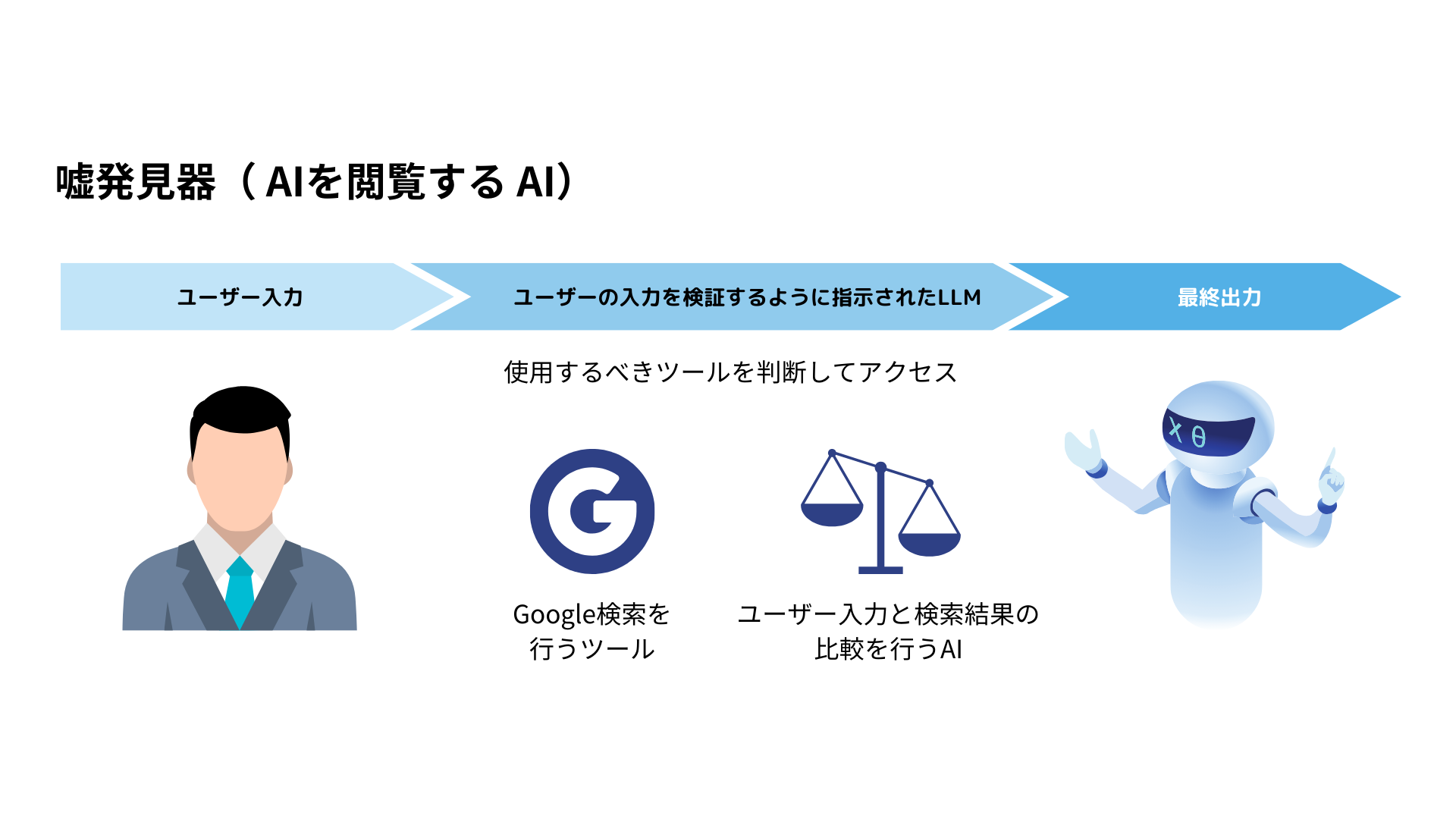
生成AIには、”ハルシネーション“という「嘘の情報を本当のことのように話す」振る舞いが問題視されています。
弊社では、様々な手法でこの問題の対処に取り組んでいますが、1つの手法として「AIを検閲するAI」の開発を行っています。
この例では、AIが生成した回答が正しいのかどうか、Google検索などので取得したデータソースにアクセスし、本当の情報であるかどうか検証しています。
他にも、論文データベースや自社の正しい情報のみが載っているデータにアクセスすることで、より高度な検閲機能の実装が可能です。
AIを使ったハルシネーション対策AIの開発に興味がある方には、まずは1時間の無料相談をご用意しております。
こちらからご連絡ください。
ハルシネーションリスクを抑えて生成AIで業務を効率化しよう
ハルシネーションとは、AIが虚偽の情報をもっともらしい形で生成してしまう現象のことです。ハルシネーションが起こる原因をまとめました。
- 学習データの誤り
- 文脈を重視した回答
- 情報が古い
- 情報の推測
AIは、インターネット上に存在する大量のデータを学習源としています。インターネット上には、誤った情報が数多く存在するので、それらを学習してしまうことで虚偽の情報が生成されてしまうというわけです。
また、生成AIが出力する情報は、質問に対して自然な形で回答しようとしているため、文章を最適化する過程で虚偽の情報が生成されることもあります。学習データに回答として有効な情報がない場合は、推測して情報を生成することもあるので注意しましょう。
ハルシネーションを社内利用する際は、以下の対策が有効です。
- 偽情報や不正確な情報を回答することを念頭におく
- ガイドラインを作成する
- 回答結果の確認プロセスを構築する
まずは、すべての従業員が生成AIの正しい使い方を理解し、出力される情報を鵜呑みにしないことが大切です。必要に応じてガイドラインなどを作成し、回答結果を確認する工程を設けるようにしましょう。
一方、生成AIを開発する側も適切な対策が必要です。
行うべき対策を以下にまとめました。
- 学習データの質の向上
- 出力の結果にフィルターをかける
- RLHF
- グラウンディング
生成AIは、学習したデータを基に情報を出力するので、質の高い情報を学習させることが大切です。闇雲に大量のデータを学習させても、出力する情報の質は上がりません。また、フィードバックを繰り返しながらAIモデルのチューニングを行うRLHFも有効です。さらに、グラウンディングやエンベディングなどを行いながら、学習データを独自で用意したデータのみに絞るというのもよいでしょう。
このように、ハルシネーションリスクは、活用する際や開発する際にいくつかの対策が行えます。自社ができる最大限の対策を行い、生成AIで業務を効率化させましょう。

生成系AIの業務活用なら!
・生成系AIを活用したPoC開発
・生成系AIのコンサルティング
・システム間API連携
最後に
いかがだったでしょうか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
 ︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。
︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。