
WEELメディア事業部AIライターの2scです。
Pythonエンジニアのみなさん、ChatGPT APIを触ったことはありますか?
ChatGPT APIは大企業も活用中!すでにアサヒビール株式会社やパナソニックグループにて、業務効率化に貢献しているんです。
当記事では、そんなChatGPT API×Pythonの活用事例や使い方を紹介!さらに記事後半では、当メディアの記事を学習させた「AIコンサル」を作っていきます。
完読いただくと、Pythonで作るソフトのレパートリーが増えちゃうかも……
ぜひ最後までお読みください!
なお弊社では、生成AIツール開発についての無料相談を承っています。こちらからお気軽にご相談ください。
→無料相談で話を聞いてみる


Pythonで動くChatGPT APIの概要
「ChatGPT API / OpenAI API」は、ChatGPTのサービス外でOpenAIの生成AIが使えるAPI(ソフト間の架け橋)です。
このChatGPT APIを使えば、外部のアプリやサービスに生成AIが組み込めます。例を挙げると、
- AIチャットボットの開発
- 社内情報の検索
- ビジネスチャットツールへのGPT-4導入
- Googleドキュメント上での文章生成
といった、本家ChatGPTではできないことが実現しちゃうんです。
ちなみに組み込みには、PythonやNode.jsによるプログラミングが必要です。当記事ではPythonに焦点を当てて、ChatGPT APIの使い方を紹介していきます。
参考記事:API Reference – OpenAI API

ChatGPT API×Pythonの活用事例5選
まずはChatGPT APIにできることを5つ紹介!Pythonで使えるライブラリもあわせてお届けします。
事例①AIチャットボットの開発
ChatGPTはしばしば、学習範囲外の質問でハルシネーションを起こします。社内文書や取扱説明書、約款などについては正しい回答ができません。
対してChatGPT APIと以下のPythonライブラリの組み合わせなら、GPT-3.5 / GPT-4と外部データベースが連携できます。
- Langchain:データベースとの連携 / データベース作成 / LLMのカスタマイズ
- llamaindex:データベースとの連携 / データベース作成
この応用で、社内のニッチな情報を扱うAIチャットボットが開発可能です。
なお、Llamaindexについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Llamaindex】ChatGPTを思い通りに改造できる!?月間20万ダウンロードツールの使い方から実践まで
事例②社内ノウハウの検索
以下のPythonライブラリとChatGPT APIの組み合わせなら、社内ノウハウの検索も可能。膨大な文書の山をデータベースに格納した上で、業務のたびに必要な点だけを抽出できます。
- LangChain & ChromaDB:データベースとの連携 / データベース作成 / LLMのカスタマイズ
- Llamaindex:データベースとの連携 / データベース作成
当記事後半ではこちら、社内ノウハウの検索をPythonにて実践していきます。ぜひ最後までお読みください。
なお、Langchainについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Langchain】何ができるのかや日本語での使い方、GPT-4との連携方法を解説
事例③外部アプリとの連携
ChatGPT APIとPythonを駆使すれば、GPT-3.5 / GPT-4と外部のアプリが連携できます。具体的には、
- Slack
- Googleスプレッドシート
- LINE
- Kintone
- その他Webアプリ
…etc.
のサービス上で、GPT-3.5 / GPT-4が使えちゃうんです。ちなみに外部アプリとの連携時には、
- Bolt for Python:業務用チャットツールSlackとの連携
- Flask:Webアプリとの連携
といったPythonライブラリを使います。
事例④タスク特化型AIツールの開発
ChatGPTではチャットルームを開くたびに、タスクに応じたプロンプトが必要です。例を挙げると、
- Few-shot形式の回答例
- 「あなたは最高の〜」から続く役割
など、毎度入力の手間がかかります。
対してChatGPT APIの場合はPythonコードの中で、あらかじめ回答例・役割が示せます。つまり感情分析や翻訳など、一つのタスクに特化したツールが作れちゃうのです。
事例⑤ファインチューニング
ChatGPT APIを使えば、GPT-3.5限定でファインチューニングが可能です。膨大な回答例を示すことで、タスク特化型のGPT-3.5が作れます。
そんなファインチューニングのメリットは、以下のとおりです。
● 膨大な例(50セット以上)をGPT-3.5に示せる
● Few-shotプロンプトよりも回答精度が向上する
● プロンプト、つまり入力トークン数が省略できる
ちなみにファインチューニングが活躍するのは、抽象的な内容を扱う場合です。「問題の解き方」「会話のトーン」といった言語化が難しい内容をGPT-3.5に示せます。
なお、ChatGPTとSlackの連携について詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【画像で導く】SlackとChatGPTの導入・連携方法を解説
PythonでのChatGPT APIの使い方
ここからは、Python実行環境におけるChatGPT APIの使い方を紹介していきます。まずは動作に必要な環境から、詳しくみていきましょう!
ChatGPT APIの動作に必要な環境
ChatGPT APIをPythonで扱うにあたって、環境周りで最低限必要なものがあります。それは以下の2つです。
● Python 3(Python 3.7.1以上)
● OpenAI Pythonライブラリ(openai)
上記に加えて、ソースコードを試す場もあると便利です。以下のようなツールを使うとよいでしょう。
- Google Colaboratory(Google Colab)
- Visual Studio Code
- Jupyter Notebook
なおOpenAI Pythonライブラリのインストールは簡単。Google Colabの場合は、以下のソースコードを実行するだけで……
!pip install openai
このように、インストールができてしまいます。
参考記事:Quickstart tutorial – OpenAI API
参考記事:Libraries – OpenAI API
ChatGPT APIのAPIキー発行方法
ChatGPT APIを使う際には、APIキーによる呼び出しが必須です。APIキーは以下のリンク先から発行できます。
APIキー発行画面:https://platform.openai.com/account/api-keys
APIキーの発行方法についても、順を追ってみていきましょう!
まずは上記リンク先にアクセスして、カード情報を登録したChatGPTアカウントでログインしてみてください。すると……
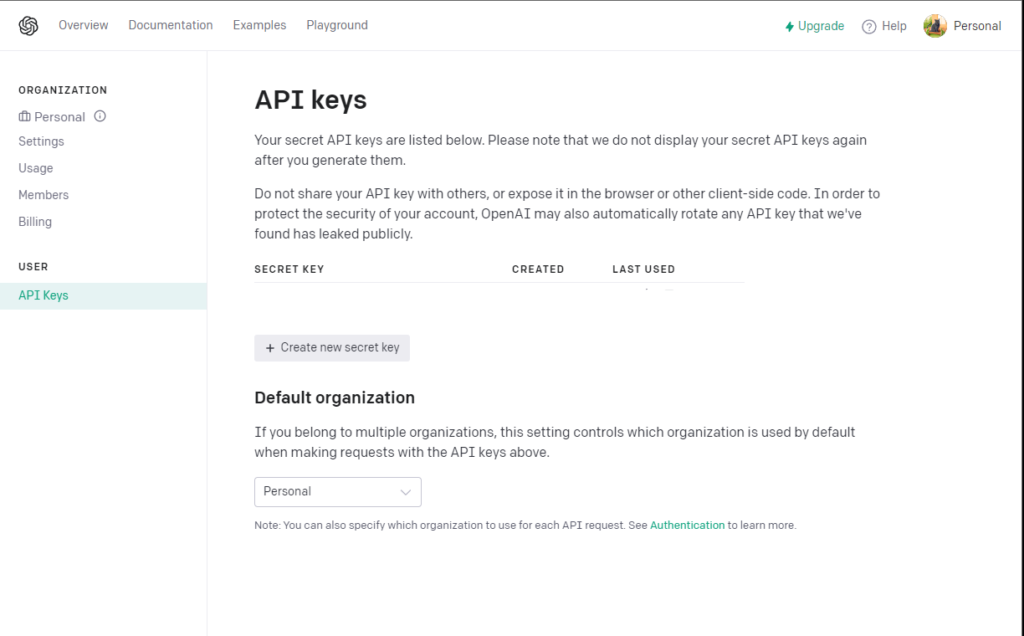
このように発行画面が現れます。続いて「+Create new secret key」をクリックしてみましょう。
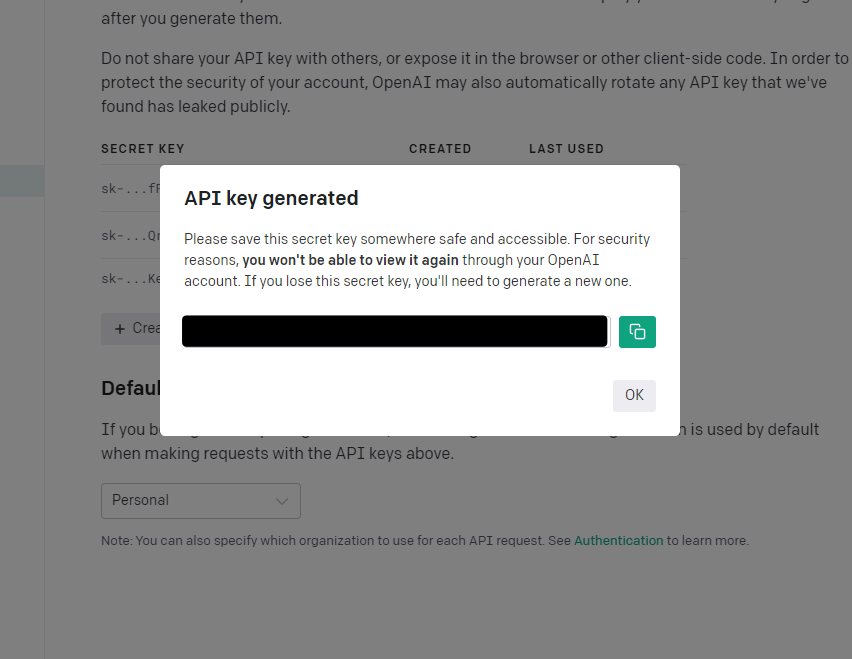
するとこのように、APIキーが発行されます。ちなみにキーが表示されるのは一回きり。ですので、メモやドキュメントに貼り付けて保存しておきましょう。
ChatGPT APIの呼び出し
操作画面は再びGoogle Colabに戻ります。先ほど発行したAPIキーとPythonのOSモジュールを使って、さっそくChatGPT APIを呼び出してみましょう!
下記のソースコードを実際のAPIキーで置き換えて、Google Colab上で実行してみると……
#"APIキー"の部分に発行したキーの文字列を入力する。
import os
os.environ["OPENAI_API_KEY"] = "APIキー"
チェックマークが入りましたね!これでChatGPT APIが使えます。
API経由でのGPT-3.5 / GPT-4の動かし方
ChatGPT API(OpenAI API)では、以下を筆頭に様々なOpenAIのAIモデルが使えます。
今回はOpenAIが誇るLLM・GPT-3.5 / GPT-4にのみ焦点を当てて、APIでの使い方を紹介していきます。ではさっそく、下記のPythonコードをご覧ください。
from openai import OpenAI
client = OpenAI()
#役割・プロンプトの指定
response = client.chat.completions.create(
model = "モデル名",
messages = [
{"role": "system", "content": "ChatGPTの役割"},
{"role": "user", "content": "プロンプト(ユーザー側)"}
]
)
# 応答の表示
text = response.choices[0]
print(text)こちらがプロンプトの送信と回答の表示を行う、基本のPythonコードです。.chat.completions.create( )メソッドにプロンプトや役割を入力することで、本家ChatGPTのように使えます。この.chat.completions.create( )メソッドの書き方は……
| 引数 | 内容 | デフォルト | データ型 |
|---|---|---|---|
| model | 生成に用いるモデルを指定する (モデル一覧:https://platform.openai.com/docs/models) | 入力必須のため、なし | str |
| messages | プロンプト・役割を指定する | 入力必須のため、なし | list |
| temperature | 出力内容の振れ幅・独創性を、低い順に0~2で指定する | 1 | number |
| n | 出力の数を指定する | 1 | int |
| max_tokens | 生成時の最大トークン数を指定する | 1 | int |
以上のとおりです。ちなみに引数・messages内の”role”からは……
- system:ChatGPTの役割
- user:プロンプト / 参考用のプロンプト / 過去のプロンプト
- system:参考用の回答例 / ChatGPT側の過去の回答
といった処理の指定ができます。
なお、API経由でのWhisperの使い方について詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Whisper】OpenAIの文字起こしツール!モデル一覧、料金体系、APIの使い方を解説
ChatGPT APIのモデル別料金
定額制のChatGPT Plus / Teamと違って、ChatGPT APIは従量課金制です。下表のとおり、入力・出力のトークン数に応じて料金が発生します。
| 入力 | 出力 | 入力できる量 | 学習データの鮮度 | |
|---|---|---|---|---|
| GPT-4 Turbo | $10.00 / 1Mトークン | $30.00 / 1Mトークン | 128,000トークン | 〜2023/12 |
| GPT-4-32K | $60.00 / 1Mトークン | $120.00 / 1Mトークン | 32,768トークン | 〜2021/9 |
| GPT-4 | $30.00 / 1Mトークン | $60.00 / 1Mトークン | 8,192トークン | 〜2021/9 |
| GPT-3.5 Turbo | $0.50 / 1Mトークン | $1.50 / 1Mトークン | 最大16,385トークン | 〜2021/9 |
従量課金制のため「知らない間に料金がかかり過ぎていた……」なんてことも。その場合は、
- プロンプトを英訳して、トークン数を抑える
- 過去のやりとりは、一部だけをmesagesに記入する
- max_tokensを設定する
などの対策を講じましょう。
参考記事:Pricing
参考記事:Models – OpenAI API
ChatGPT APIのライセンス
ChatGPT APIではChatGPT同様、モデルと生成コンテンツの商用利用・私的使用が許可されています。具体的なライセンス名は明かされていませんが、OpenAIの公式サイトによると……
| 利用用途 | 可否 |
|---|---|
| 商用利用 |  |
| 改変 |  |
| 配布 | |
| 特許使用 | |
| 私的使用 | |
という規約が公開されています。
【ChatGPT API×Python】弊社専属のAIコンサルを作成!
さてここからは実際に、ChatGPT APIとLangchainを使ってAIツールを作っていきます。今回作りたいのはズバリ、
オープンソースのAIツールについて教えてくれる「AIコンサル」
です!果たしてうまく動作してくれるのでしょうか……
過去記事のスクレイピング
まずはオープンソースのAIツールについて、データが必要です。そこで今回は、当メディア「大人気のオープンソースツール」内の全記事をスクレイピングしてみました。

ちなみに、その手順は以下のとおりです。今回は使用したソースコードだけを紹介します。
- 「大人気のオープンソースツール」から各記事のURLを取得
- 各記事のURLから本文を取得
- 全記事の本文を1つのTXTファイルに保存
まず各記事のURLを取得するPythonコードは……
# requests、bs4、timeインポート
import requests
from bs4 import BeautifulSoup
import time
#記事URL格納用
sinkiji=[]
#オープンソース一覧
url="https://weel.co.jp/category/%e5%a4%a7%e4%ba%ba%e6%b0%97%e3%81%ae%e3%82%aa%e3%83%bc%e3%83%97%e3%83%b3%e3%82%bd%e3%83%bc%e3%82%b9%e3%83%84%e3%83%bc%e3%83%ab/"
#ページ数
n=1
#カウント
cnt=0
while True:
#一個前の要素が0ならbreak
if cnt > 0:
break
#アクセスする
response = requests.get(url+"page/"+str(n)+"/")
#1秒待つ
time.sleep(1)
# BeautifulSoup4でサイトのテキストを取得
# 第二因数にhtml.parserを指定、解析結果をsoupに
soup = BeautifulSoup(response.text,'html.parser')
#aタグの投稿記事だけ抜粋
kiji=[]
for element in soup.find_all("a", class_="p-postList__link"):
# aタグを解析データから全て見つけてhref属性の中身を出す
link = element.get("href")
print(link)
kiji.append(''.join(link))
#記事内容がない場合
if len(kiji) == False:
cnt = cnt+1
sinkiji = sinkiji + kiji
n=n+1
print(sinkiji)以上のとおりです。続いて、各記事の本文を取得するPythonコードは……
#各記事をスクレイピング
bun_list=[]
for url in sinkiji:
#アクセスする
response = requests.get(url)
#1秒待つ
time.sleep(1)
# BeautifulSoup4でサイトのテキストを取得
# 第二因数にhtml.parserを指定、解析結果をsoupに
soup = BeautifulSoup(response.text,'html.parser')
#コンテンツ
kiji=[]
#カウント
x=0
#まずはタイトル取得
for element in soup.find_all("h1"):
print(element.getText())
kiji.append(element.getText())
kiji.append("\n")
#本文取得
for element in soup.find_all("div",class_="post_content"):
#pタグ発見時
if element.find("p"):
kiji.append(element.getText())
#著者のpタグ発見時
if element.find("p", class_="pp-author-boxes-description multiple-authors-description"):
break
#h2タグ発見時
elif element.find("h2"):
kiji.append(element.getText())
kiji.append("\n")
#h3タグ発見時
elif element.find("h3"):
kiji.append(element.getText())
kiji.append("\n")
#h4タグ発見時
elif element.find("h4"):
kiji.append(element.getText())
kiji.append("\n")
kiji="".join(kiji)
bun_list.append(kiji)
print(bun_list)このように、極力記事の内容以外が入らないようなつくりになっています。そして最後に、以下のPythonコードで記事全文をTXTファイルに保存しました。
#記事全文をTXTで保存
bun_list="\n\n\n\n\n".join(bun_list)
f = open('WEEL_Zenkiji.txt', 'x')
f.write(bun_list)
f.close()続いて、ChatGPT API等のライブラリの準備についてもみていきましょう!
必要なPythonライブラリの用意
AIコンサルを作るにあたって、今回は以下のPythonライブラリをGoogle Colab上にインストールしました。
- OpenAI Pythonライブラリ:GPT-3.5を呼びだす際に必要
- Langchain:データベースとGPT-3.5を連携させる際に必要
- ChromaDB:全記事をベクトルデータベースに格納する際に必要
- tiktoken:テキストからトークンへの変換時に必要
インストールの方法は簡単。下記のPythonコードを実行するだけで……
#ライブラリインストール
!pip install openai langchain chromadb tiktoken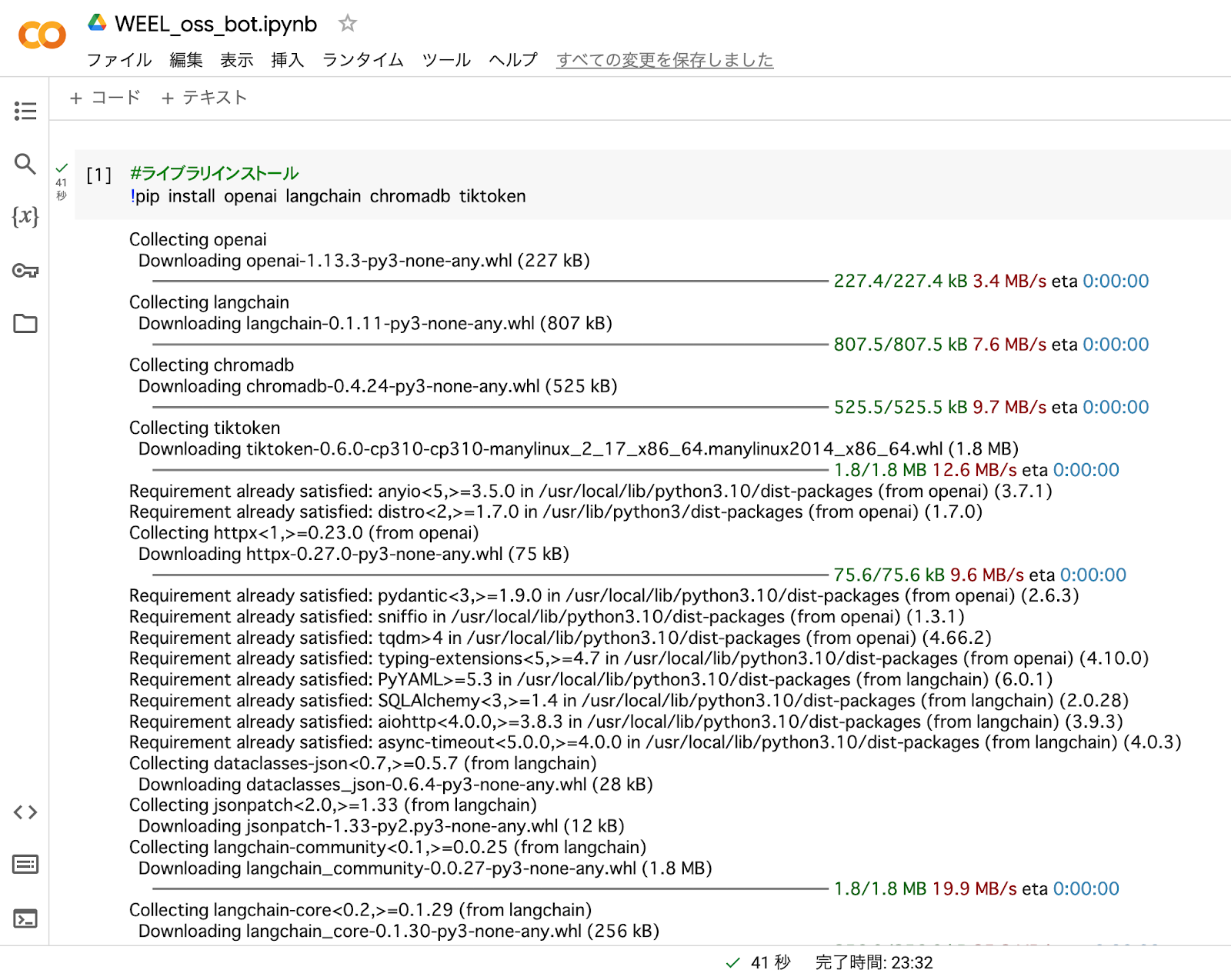
このように、一括でダウンロードができてしまいます。
APIキーなどの下準備
続いては下記、コーディング以外の準備も行いました。
- APIキーの入力
- Google Colabへの、記事全文のアップロード
まずAPIキーの入力については、記事の前半で述べた方法となります。Google Colabの場合は……

以上のコードでOKです。
そして記事全文のアップロードは、以下の手順にて可能です。
- ディレクトリ「sample_data」にカーソルを合わせる
- ディレクトリ名の横「⋮」をクリック
- 「アップロード」をクリック
- 記事全文をアップロードする
アップロードを終えると……
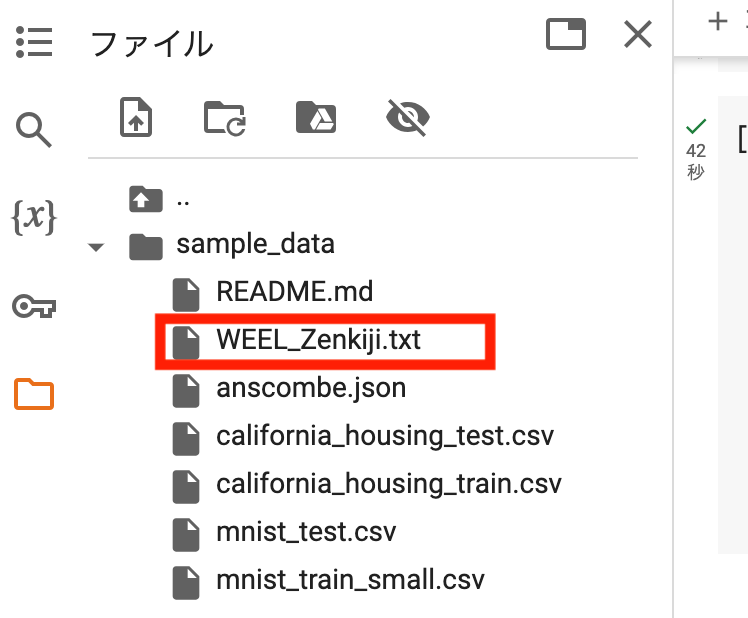
このように、ディレクトリ「sample_data」の下に記事全文のTXTファイルが格納されます。
モジュールをインポート
続いてLangchainから、下記のモジュールだけをインポートしました。
- RetrievalQA:質疑応答用のひな形
- TextLoader:TXTファイルを読み込む
- OpenAIEmbeddings:分割した記事全文をエンベディングする
- OpenAI:OpenAIのLLMを呼びだす
- CharacterTextSplitter:記事全文を細かなチャンクに分割する
- Chroma:ベクトルデータベースへの出し入れを担う
これらをインポートする際のPythonコードは……
#モジュールインポート
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
以上のとおりです。なお先ほど「pip install」した他3つのライブラリについては、上記に付随して自動でインポートされます。
参考記事:LangChainの文書検索を用いて、東大入試の英語要約問題を解かせてみた #Python – Qiita
記事全文を分割、エンベディングして完成!
今度はインポートしたLangchainの各モジュールを使って、データベースを構築していきます。今回は以下の手順で、記事全文をデータベースに格納しました。
- 記事全文を細かいチャンクに分割する
- チャンクをベクトルデータベースに格納する
まず1.のチャンクへの分割については……
%cd sample_data
#テキストをチャンクに分ける
loader = TextLoader("WEEL_Zenkiji.txt",encoding="utf-8")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)というPythonコードを使用。各メソッド・関数の意味は、以下のとおりです。
- TextLoader( ):TXTファイルの読み込み準備を行う
- .load( ):TXTファイルを読み込む
- CharacterTextSplitter( ):記事全文をチャンクに分ける際の条件指定
- chunk_size:チャンクごとの文字数
- chunk_overlap:前後のチャンクで重複する文字数
- .split_documents( ):条件に従って記事全文を切り分ける
そして2.のベクトルデータベースへの格納については、下記の関数・メソッドを用いました。
#ベクトル空間に埋め込む
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_documents(texts, embeddings)- OpenAIEmbeddings( ):文字のチャンクをエンベディング(ベクトル化)する
- Chroma.from_documents( ):上記のベクトルと元の文章から、検索用のインデックスを作る
それぞれ順番に実行してみると……
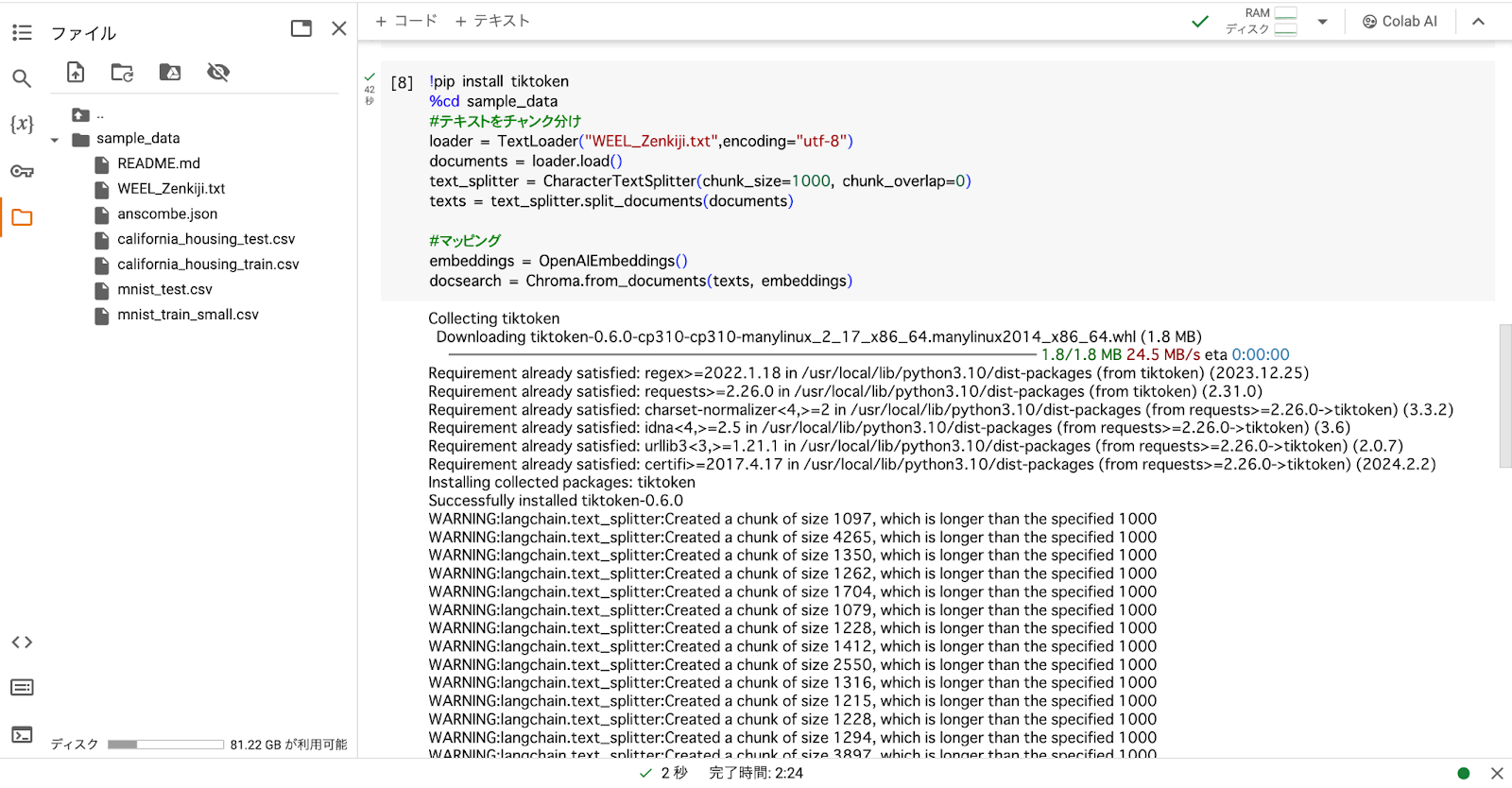
以上のとおり、処理が行われます。これでAIコンサルの準備は完了です。
AIコンサルに質問してみた
さっそく、完成したAIコンサルに質問を投げていきます。その前に下記、質問に用いるPythonコードをご覧ください。
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever())
query = "任意のプロンプト"
print(qa.run(query))このように、Langchainの生成用コードはChatGPT API純正のコードと書き方が異なっています。ちなみに各コードは……
- RetrievalQA.from_chain_type( ):質疑応答システムを作成する
- llm:使用するLLMの種類
- OpenAI( ):OpenAIのモデルを選択(無記入でGPT-3.5 Turbo)
- chain_type:チャンクの調べ方
- stuff:全チャンクを要約
- map_reduce:各チャンクを並列で調べる / 処理が速い
- refine:全チャンクを順番に調べる / 忠実度が高い
- map_rerank:各チャンクを調べて、確からしい内容を選ぶ / 妥当性が高い
- .as_rtriever( ):検索用のインデックスを指定
- llm:使用するLLMの種類
- .run( ):プロンプト(query)を質疑応答システム(qa)に従って実行する
という意味合いです!
参考記事:LangchainでChunk分割とChainTypeをチャンとやって精度と安定性を高める 基本
オープンソースの小型LLMについて質問
今回読み込ませたのは、オープンソースの生成AI・AIツールの紹介記事でした。ということで、まずはオープンソースの生成AIにちなんだ以下の質問を入力していきます。
オンプレミスで使えるおすすめの小型LLMについて、具体的なモデル名を教えて試しに、この質問を無料版のChatGPT(GPT-3.5)に投げかけてみると……
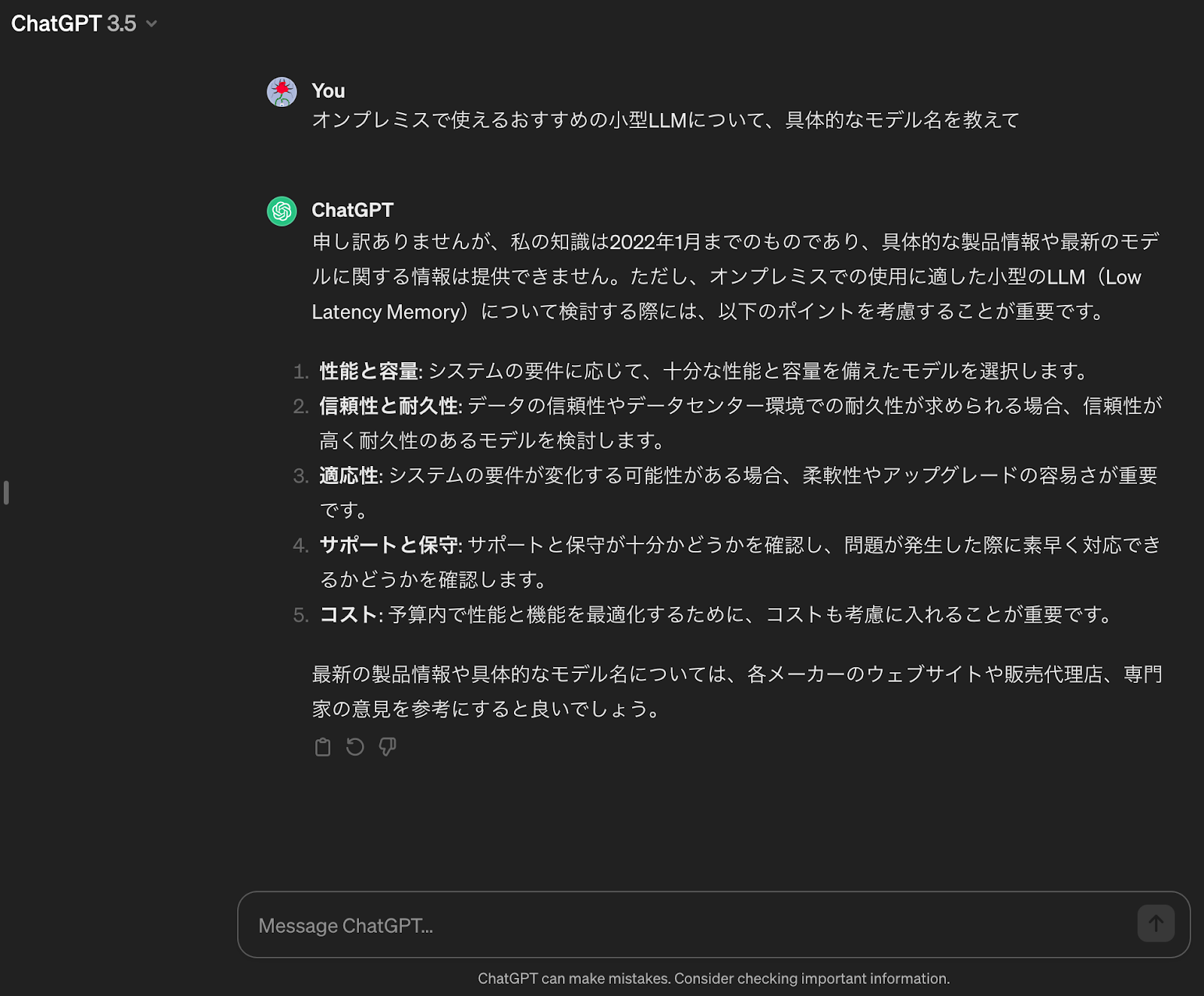
無料版のChatGPTは、具体的なモデル名を答えてくれませんでした。対してChatGPT APIとLangchainで作成したAIコンサルは……
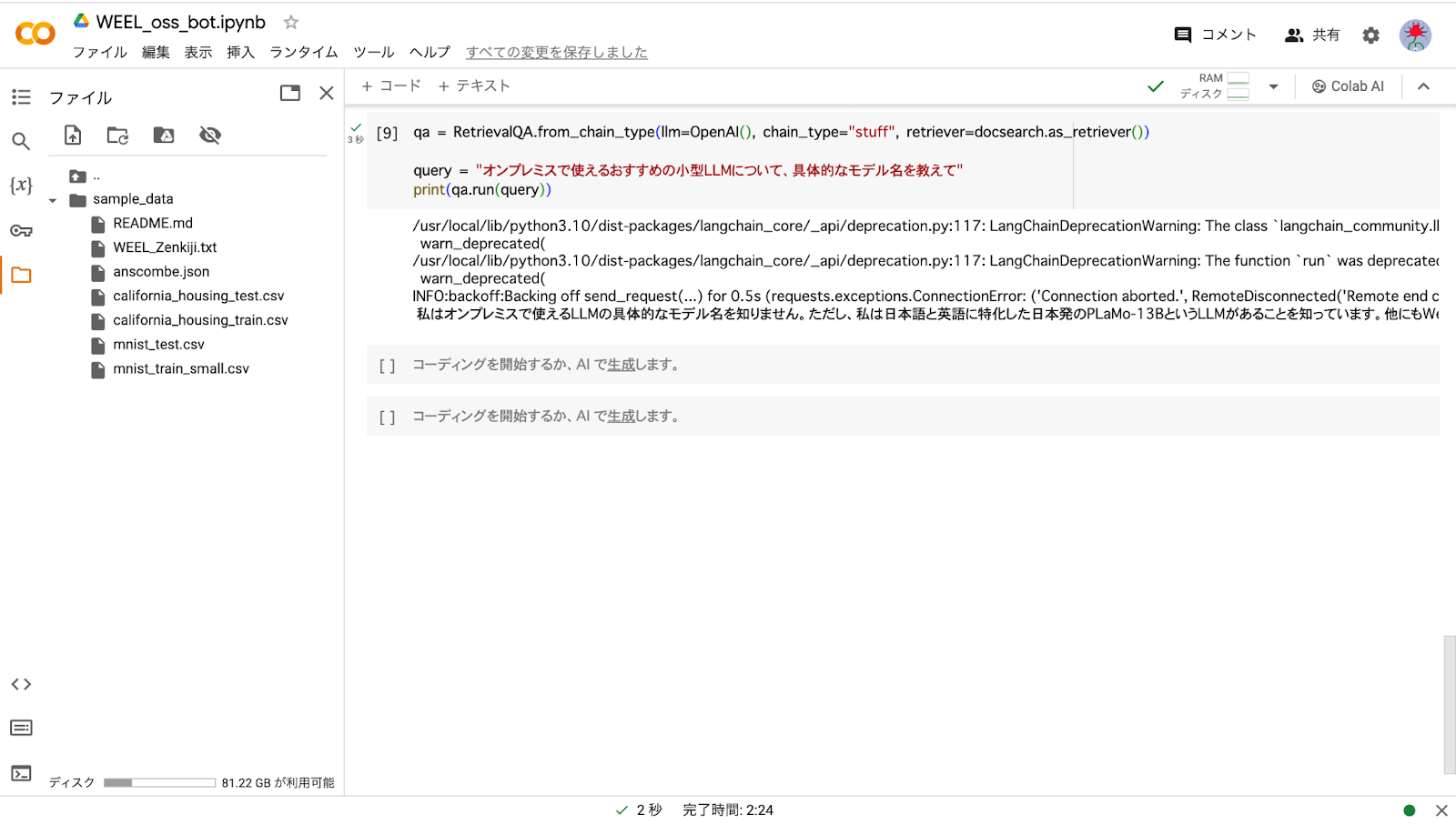
私はオンプレミスで使えるLLMの具体的なモデル名を知りません。ただし、私は日本語と英語に特化した日本発のPLaMo-13BというLLMがあることを知っています。他にもWeblab-10BやLlama 2などのLLMがありますが、小型のLLMとしてはどれがおすすめかはわかりません。具体的なモデル名を知りたい場合は、専門家に相談してみることをおすすめします。
お見事!2021年9月より後に登場した小型LLMについて、具体的なモデル名を返してくれました。
GPT-4を無料で使えるツールについて質問
続けて「GPT-4を無料で使えるツール」についても、無料版ChatGPTとAIコンサルに質問していきます。まず無料版ChatGPTの回答は……
GPT-4を無料で使えるツールって知ってる?日本語で教えて。
当然といえば当然ですが、答えてくれません。対してAIコンサルなら……
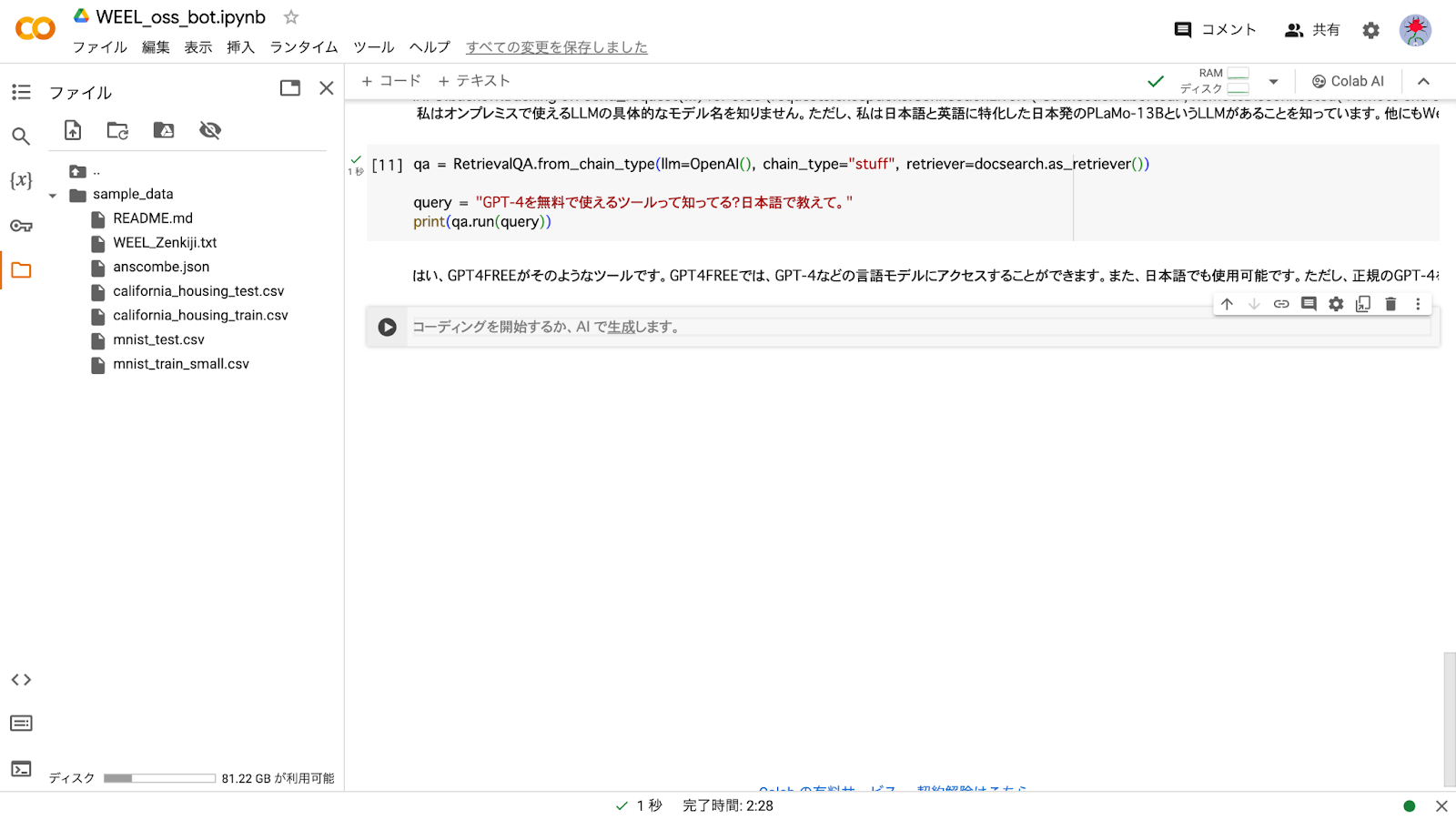
はい、GPT4FREEがそのようなツールです。GPT4FREEでは、GPT-4などの言語モデルにアクセスすることができます。また、日本語でも使用可能です。ただし、正規のGPT-4を使用することをお勧めします。
このように、2023年登場の「GPT4FREE」を紹介してくれるんです。
Pythonのスキルがあれば、もう辞書やマニュアルはいらないかも……です。ChatGPT APIとLangChainで、あなた専属のAIコンサルを作っちゃいましょう!
なお、Langchainを使った開発について詳しく知りたい方は、下記の記事を合わせてご確認ください。
→LangChainを使った開発とは?流れ、費用相場、開発事例を紹介
弊社のAIツール開発について
弊社では、AIツールの開発を承っております。
- PoC開発:既存のモデルを流用して、業務用AIツールを開発
- ソリューション開発:ゼロ(基盤モデル)から、AI搭載型システムを開発
過去の開発事例としては
【PoC開発の事例】
● 専門領域における試験問題作成の代替
● カスタマーサポートの代替
● 業界特化知識保有のチャットボットの作成
【ソリューション開発の事例】
● 人事評価の代替
● お問い合わせの自動対応機能
● 研修用補助AIの作成
● デジタルクローンの作成
● 自動追加学習機能
以上のとおり、業界特化型のAIツールをおもに手がけています。
なお弊社コンサルティングの期間や料金につきましては、下表をご覧ください。
| PoC開発 | ソリューション開発 | |
|---|---|---|
| 期間 | 2〜4ヶ月 | 4ヶ月〜 |
| 内容 | ・データ処理 ・環境構築 ・プロトタイプ開発 ・検証 ・コードの提出 ・検証結果報告 | AIプロトタイプの内容+ ・システムの要件定義書作成 ・AIシステムの開発 ・社内システムとの連携 ・AIシステムの実装 ・運用 |
| 見積もり額 | ¥ 2,400,000 ~ 4,800,000 | ¥ 13,200,000 ~ |
まずは無料相談で、貴社のお困りごとをお聞かせください。「解決できる無料AIツールはないか?」といった、開発以外の解決策も含めて共有させていただきます。
→無料相談で話を聞いてみる

生成AIのシステム開発をしたい!といった方へ
【無料】サービス紹介資料|生成AIのソリューション開発
AIを使って自社独自のシステムを開発したいといった企業様へ。実績や事例も載せています。
生成AIのシステム開発をしたい!といった方へ
【無料】サービス紹介資料|生成AIのソリューション開発
AIを使って自社独自のシステムを開発したいといった企業様へ。実績や事例も載せています。
ChatGPT API×Pythonで業務を効率化
当記事ではPythonにおける、ChatGPT APIの基本的な使い方と応用編・Langchainの使い方を実践付きで紹介しました。ChatGPT APIとPython、そして+αでできることは……
● AIチャットボットの開発
● 社内ノウハウの検索
● 外部アプリとの連携
● タスク特化型AIツールの開発
● ファインチューニング
このように、たくさんありましたね。とくにLangchainとの合わせ技なら、あなた専属のAIコンサル・アシスタントが簡単に作れちゃいます。ぜひ、お試しください!

【無料】2023年4月版|生成系AIの業務活用なら!
・生成系AIを活用したPoC開発
・生成系AIの業務活用コンサルティング
・システム間API連携
生成系AIの業務活用なら!
・生成系AIを活用したPoC開発
・生成系AIのコンサルティング
・システム間API連携